選択肢が3つ以上ある離散選択問題を扱う際、一般的には多項ロジットモデルがよく使われますが、別の選択肢として多項プロビットモデルも存在します。
多項プロビットモデルって別に新しい手法というわけでもないと思うんですが、ふと「多項プロビットモデルのMCMCってどうやるんだろう?」と思って調べた際、書籍やweb情報がほとんど見つけられませんでした。
(調べ方が悪いのか、日本語は1つも見つけられなかった…)
唯一、一昨年に第2版が出版された『Bayesian Statistics and Marketing』に詳細な情報が載っているのを見つけることができました。
なので今回は『Bayesian Statistics and Marketing』を参考に、多項プロビットモデルのモデル式やNumPyroを使ったMCMC実装を解説します。
多項プロビットモデルのモデル式
離散選択問題では、「個体$i$が複数の選択肢($1\sim P$)の中から選択肢$j$を選ぶとき、効用$z_{ij}$が得られる」と考えます。この効用$z_{ij}$を、説明変数\boldsymbol{x_{ij}}$ ・回帰係数$\boldsymbol{\delta}$・誤差項$v_{ij}$の線形和として、以下のようにモデル化します。
$$
\begin{aligned}
z_{ij} &= \boldsymbol{x_{ij}’\delta} + v_{ij} \\
&= \delta_0 + \delta_1 x_{ij1} + \delta_2 x_{ij2} + \dots + v_{ij}
\end{aligned}
$$
個体$i$の選択結果を$y_i$とすると、効用$z_{ij}$が最大となる選択肢$j$が選択されます。
$$
y_i = \operatorname*{argmax}_{j} z_{ij}
$$
誤差項 $v_{i\cdot}$ が多変量正規分布に従う場合、このモデルを多項プロビットモデル*呼びます。(ガンベル分布なら多項ロジットモデル)
$$
\left(\begin{matrix}v_{i1} \\ v_{i2} \\ \vdots \\ v_{iP}\end{matrix}\right) \sim MVN(0, \Omega)
$$
多項ロジットと比較した多項プロビットのメリットは、多変量正規分布の共分散$\Omega$による選択肢間の相関構造が存在することで、多項ロジットモデルがもつIIA特性の問題を回避できる点です。
▼IIA特性とは (折りたたみ)識別性の問題
上記モデルのパラメータ$\delta$や$\Omega$を推定したいところですが、実はこのままでは識別できません。これは、効用$z_{ij}$が位置と尺度の両方で不変だからです。
位置の不変性
たとえば、任意の定数$c$を各$z_{ij}$に足しても、効用間の大小関係は変化せず選択結果$y_i$は変わらないので、切片$\delta_0$の値が定まりません。
($\delta_0^*=\delta_0 + c$としても、効用の大小関係が一切変化しないという位置に関する不変性がある)
$$
\begin{gather*}
z_{i1}^* = z_{i1} + c = (\delta_0 + c) + \delta_1 x_{i11} + \dots + v_{i1} \\
z_{i2}^* = z_{i2} + c = (\delta_0 + c) + \delta_1 x_{i21} + \dots + v_{i2} \\
\vdots \\
z_{iP}^* = z_{iP} + c = (\delta_0 + c) + \delta_1 x_{iP1} + \dots + v_{iP}
\end{gather*}
$$
この位置に関する不変性を回避する方法の1つは、基準となる選択肢を1つ決め、基準との差分で潜在効用を定義することです。例えば、一番最後の選択肢$P$を基準として、選択肢$j$(ただし、$j \neq P$)の潜在効用$w_{ij}$を以下のように定義します。
$$
\begin{align*}
w_{ij} &= z_{ij} – z_{iP} \\
& = (\boldsymbol{x}_{ij} – \boldsymbol{x}_{iP})’\boldsymbol{\delta} + (v_{ij} – v_{iP})
\end{align*}
$$
そして、選択肢$P$の効用は$w_{iP}=0$と固定されます。つまり、選択肢$P$と比較した相対的な効用を用いていることになります。
ここで、$\boldsymbol{x}_{ij} – \boldsymbol{x}_{iP}$の計算をすることでどうなるか、もう少し深掘りしてみます。いま、説明変数として
- 1. 各個体に固有の変数が$n_d$個
- 例:個人$i$の性別、年齢、年収
- 同じ変数でも、各選択肢$1 \sim P$に与える影響はそれぞれ異なるとする
- 2. 個体×選択肢に固有の変数:$n_a$個
- 例:個人$i$が購買したときの商品$j$の販売価格、個人$i$が商品$j$の広告に接触した回数、など
があるとすると、個体$i$の説明変数行列$X_i$は、切片のための定数1も入れると以下のようになります。
$$
\begin{align*}
\underset{(P \times D)}{X_i} &= \begin{bmatrix} \boldsymbol{x_{i1}}’ \\ \vdots \\ \boldsymbol{x_{iP}}’ \end{bmatrix}\\
&= \begin{bmatrix}
\underbrace{
\begin{matrix}
1 & 0 & \cdots & 0 \\
0 & 1 & \cdots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & 1
\end{matrix}
}_{P \times P} &
\underbrace{
\begin{matrix}
d_{i,1} & 0 & \cdots & 0 \\
0 & d_{i,1} & \cdots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & d_{i,1}
\end{matrix}
}_{P \times P} &
\begin{matrix}
\cdots \\
\cdots \\
\vdots \\
\cdots
\end{matrix} &
\underbrace{
\begin{matrix}
d_{i,n_d} & 0 & \cdots & 0 \\
0 & d_{i, n_d} & \cdots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & d_{i,n_d}
\end{matrix}
}_{P \times P} &
\underbrace{
\begin{matrix}
a_{i,1,1} & a_{i,1,2} & \cdots & a_{i,1,n_a} \\
a_{i,2,1} & a_{1,2,2} & \cdots & a_{i,2,n_a} \\
\vdots & \vdots & \ddots & \vdots \\
a_{i,P,1} & a_{i,P,2} & \cdots & a_{i,P,n_a}
\end{matrix}
}_{P \times n_a}
\end{bmatrix}
\end{align*}
$$
(ただし、$D=P+(P \times n_d)+n_a$です。)
ここで$\boldsymbol{x_{iP}}$を引くと、
$$
\begin{align*}
\underset{(P \times D)}{X_i} – 1_P \boldsymbol{x_{iP}}’ &= \begin{bmatrix} \boldsymbol{x_{i1}} – \boldsymbol{x_{iP}})’ \\ \vdots \\ (\boldsymbol{x_{iP}} – \boldsymbol{x_{iP}})’ \end{bmatrix} \\
&= \begin{bmatrix}
\underbrace{
\begin{matrix}
1 &\! 0 &\! \cdots &\! \textcolor{#1C86EE}{-1} \\
0 &\! 1 &\! \cdots &\! \textcolor{#1C86EE}{-1} \\
\vdots &\! \vdots &\! \ddots &\! \textcolor{#1C86EE}{\vdots} \\
\textcolor{red}{0} &\! \textcolor{red}{0} &\! \textcolor{red}{\cdots} &\! \textcolor{red}{0}
\end{matrix}}_{P \times P} &\!\!\!
\underbrace{
\begin{matrix}
d_{i,1} &\! 0 &\! \cdots &\! \textcolor{#1C86EE}{-d_{i,1}} \\
0 &\! d_{i,1} &\! \cdots &\! \textcolor{#1C86EE}{-d_{i,1}} \\
\vdots &\! \vdots &\! \ddots &\! \textcolor{#1C86EE}{\vdots} \\
\textcolor{red}{0} &\! \textcolor{red}{0} &\! \textcolor{red}{\cdots} &\! \textcolor{red}{0}
\end{matrix}
}_{P \times P} &\!\!\!
\begin{matrix}
\cdots \\
\cdots \\
\vdots \\
\cdots
\end{matrix} &\!\!\!
\underbrace{
\begin{matrix}
d_{i, n_d} &\! 0 &\! \cdots &\! \textcolor{#1C86EE}{-d_{i, n_d}} \\
0 &\! d_{i, n_d} &\! \cdots &\! \textcolor{#1C86EE}{-d_{i, n_d}} \\
\vdots &\! \vdots &\! \ddots &\! \textcolor{#1C86EE}{\vdots} \\
\textcolor{red}{0} &\! \textcolor{red}{0} &\! \textcolor{red}{\cdots} &\! \textcolor{red}{0}
\end{matrix}}_{P \times P} &\!\!\!
\underbrace{
\begin{matrix}
a_{i,1,1} – a_{i,P,1} &\!\!\! a_{i,1,2} – a_{i,P,2} &\!\!\! \cdots &\!\!\! a_{i,1,n_a} – a_{i,P,n_a} \\
a_{i,2,1} – a_{i,P,1} &\!\!\! a_{i,2,2} – a_{i,P,2} &\!\!\! \cdots &\!\!\! a_{i,2,n_a} – a_{i,P,n_a} \\
\vdots &\!\!\! \vdots &\!\!\! \ddots &\!\!\! \vdots \\
\textcolor{red}{0} &\!\!\! \textcolor{red}{0} &\!\!\! \textcolor{red}{\cdots} &\!\!\! \textcolor{red}{0}
\end{matrix}}_{P \times n_a}
\end{bmatrix}
\end{align*}
$$
上式の色つき部分を見てみると、
- 赤色の行:全ての要素が0なので不要
- 青色の列:全ての要素が同じ値なので不要 (効用間の大小関係に影響を与えないため)
となり、説明変数行列から取り除けることが分かります。よって$\boldsymbol{x_{iP}}$を引き、不要な要素を削除した説明変数行列を新たに$\tilde{X_i}$とすると、潜在効用$\boldsymbol{w_i}=(w_{i1},\dots,w_{i(P-1)})’$は
$$
\boldsymbol{w_i} \sim MVN\left(\tilde{X_i} \boldsymbol{\beta}, \Sigma \right)
$$
と書けます。ただし、$\tilde{X_i}$の列数および$\boldsymbol{\beta}$の次元数$\tilde{D}$は、
$$
\tilde{D} = (P-1) + (P-1) \times n_d + n_a
$$
となり、$\tilde{X_i}$の行数および$\Sigma$の行数・列数は$P-1$となります。
尺度の不変性
これで位置の不変性は解消しますが、まだ尺度に関する不変性が残っています。というのも、上式の$\boldsymbol{w_i}$に正の定数$c$をかけ、$c\boldsymbol{w_i}$にしても、やはり潜在効用の間の大小関係に影響を与えません。
この問題の解消方法もいくつかあるのですが、今回は$\Sigma$の(1,1)要素を$\sigma_{1,1}=1$に固定する方法を採用します。
さらに、$\Sigma$を標準偏差ベクトル $\boldsymbol{\sigma}$と相関行列$R$に分解して以下のように定義します。
$$
\Sigma = \text{diag}(\boldsymbol{\sigma})\, R\, \text{diag}(\boldsymbol{\sigma})
$$
ここで $\boldsymbol{\sigma} = (1, \sigma_2, \ldots, \sigma_{P-1})’$は標準偏差ベクトル($\sigma_1 = 1$ は識別制約)、$R$ は $(P-1)\times(P-1)$ 相関行列です。$\Sigma_{11} = \sigma_1^2 R_{11} = 1$ が自動的に成り立ちます。
MCMCでは $\Sigma$ のコレスキー因子を用いて計算します:
$$
L_\Sigma = \text{diag}(\boldsymbol{\sigma})\, L_R
$$
ここで $L_R$ は $R = L_R L_R’$ を満たす下三角行列です。
この分解のメリットは、スケール($\sigma_{\text{rest}} = (\sigma_2, \ldots, \sigma_{P-1})’$)と相関($R$)を独立に事前分布を設定できる点にあります。例えば$R$にはLKJ分布、$\sigma_{\text{rest}}$には半正規分布などを使うことができます。
▼LKJ分布とは (折りたたみ)ここまでをまとめると、モデル式は以下のようになります。
$$
\begin{gather*}
\boldsymbol{w_i} =\left(\begin{matrix}w_{i1} \\ \vdots \\ w_{i(P-1)} \end{matrix}\right)\sim MVN\left(\tilde{X_i}\boldsymbol{\beta}, \Sigma \right) \\
y_i = \begin{cases}
\displaystyle\operatorname*{argmax}_{1 \leq j \leq P-1} w_{ij} & \text{if } \displaystyle\max_{1 \leq j \leq P-1} w_{ij} > 0 \\
P & \text{if } \displaystyle\max_{1 \leq j \leq P-1} w_{ij} \leq 0 \end{cases} \\
\Sigma = \text{diag}(\boldsymbol{\sigma})\, R\, \text{diag}(\boldsymbol{\sigma}), \\
\boldsymbol{\sigma} = (1, \sigma_2, \ldots, \sigma_{P-1})’, \\
R:\text{相関行列}
\end{gather*}
$$
潜在効用$w$の事後分布
HMCによるサンプリングが難しい理由
上記のモデルをStanなどのPPLで実装し、ハミルトニアンモンテカルロ(HMC)によるMCMCでパラメータ推定したいところですが、実はそうはいきません。
繰り返しになりますが、$\beta, \Sigma$ が所与のとき、$\boldsymbol{w}_i$は多変量正規分布にしたがいます。
$$\boldsymbol{w}_i \sim MVN(\boldsymbol{\mu}_i,\ \Sigma), \qquad \boldsymbol{\mu}_i \equiv \tilde{X}_i\beta$$
ただし観測された選択$y_i$によって$\boldsymbol{w}_i$に制約が課されるため、$\boldsymbol{w}_i$を積分消去した周辺尤度$p(y_i \mid \beta, \Sigma)$ は、例えば$y_i=p$(ただし$p \neq P$)のとき
$$p(y_i = p \mid \beta, \Sigma) = P\!\left(w_{ip} > 0,\ w_{ip} > w_{ij}\ \forall j \neq p\right)$$
という多変量正規分布の直交領域の確率になります。これは $P \geq 4$(積分の次元が3以上)では解析的な閉形式が存在せず、計算コストの高いモンテカルロ積分が必要になります。よって、HMCのために対数尤度をコードとして記述することができません。
$w_{i,j} \mid w_{i,-j}$の分布
ここで一旦、$\boldsymbol{w_i}$の要素$w_{i,j}$について、他の要素$w_{i,-j}=(w_{1,1},\dots,w_{i,j-1},w_{i,j+1},\dots,w_{i,P-1})’$を所与としたときの条件つき分布$w_{i,j} \mid w_{i,-j}$を考えてみます。多変量正規分布の性質から、$w_{i,j} \mid w_{i,-j}$の分布は以下の1変量正規分布になります。
$$w_{i,j} \mid w_{i,-j} \sim \mathcal{N}(\mu_{j \mid -j},\ \sigma^2_{j \mid -j})$$
ただし、
$$
\begin{gather*}
\mu_{j \mid -j} = \mu_{i,j} + \Sigma_{j,-j}\Sigma_{-j,-j}^{-1}\left(\boldsymbol{w}_{i,-j} – \boldsymbol{\mu}_{i,-j}\right), \\
\sigma^2_{j \mid -j} = \Sigma_{jj} – \Sigma_{j,-j}\Sigma_{-j,-j}^{-1}\Sigma_{-j,j}
\end{gather*}
$$
です。導出については、以下の記事をご参照ください。
さらに選択肢の観測値$y_i$の制約を加えると、$w_{i,j} \mid w_{i,-j}$は以下のような切断正規分布になります。
- $y_i = P$のとき:効用$w_{i,j}$は必ず負の値をとる
$$w_{i,j} \mid w_{i,-j},\ y_i = P,\ \beta,\ \Sigma \sim TN(\mu_{j \mid -j},\ \sigma^2_{j \mid -j};\ -\infty,\ 0)$$ - $y_i = p$(ただし$p \neq P$)のとき: さらに2つのケースに分かれる
- $j = p$の場合: $w_{i,j}$は$w_{i,-j}$のどの要素よりも大きい値をとる
$$w_{i,p} \mid w_{i,-p},\ y_i = p,\ \beta,\ \Sigma \sim TN\!\left(\mu_{p \mid -p},\ \sigma^2_{p \mid -p};\ \max\!\left(0,\ \max_{k \neq p} w_{i,k}\right),\ +\infty\right)$$ - $j \neq p$の場合:$w_{i,j}$は$w_{i,p}$よりも小さい値をとる
$$w_{i,j} \mid w_{i,-j},\ y_i = p,\ \beta,\ \Sigma \sim TN(\mu_{j \mid -j},\ \sigma^2_{j \mid -j};\ -\infty,\ w_{i,p})$$
- $j = p$の場合: $w_{i,j}$は$w_{i,-j}$のどの要素よりも大きい値をとる
いずれも1次元の切断正規分布であり、逆CDF法などで容易にサンプリングできます。
つまり、HMCではなくGibbsサンプラーであれば、$w_{i,1}, w_{i,2},\dots$と順に事後分布からサンプリングすることが可能です。
NumPyroによる実装
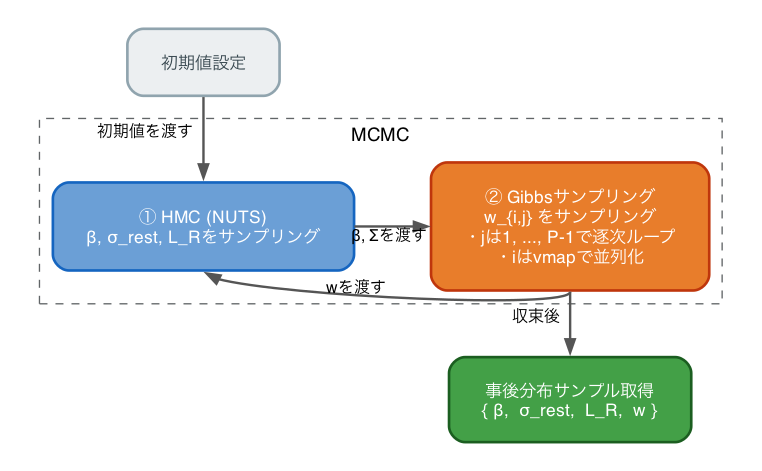
NumPyroには、一部変数にはHMCを、他の変数にはGibbsサンプラーを適用するHMCGibbsというカーネルが用意されています。つまり、$\boldsymbol{w}$の事後分布のサンプリングにはGibbsサンプラーを使い、$\beta, \Sigma$のサンプリングにはNUTS(HMC)を使うことができます。
(ただし、Gibbsサンプラー部分は自前で実装する必要あり)
そこで今回は、多項プロビットのMCMCをNumPyroを使って実装してみます。
実は$\beta, \Sigma$も、事前分布や設計次第ではGibbsサンプラーが使えます。「どうせ$w$を自前で実装するんだったら、いっそ全部Gibbsサンプリングにしたほうがいいのでは??」と若干思いながら、この記事を書いています…。
w:Gibbsサンプリング(自前実装)beta,sigma_rest,R_chol:NUTS
使用するデータは、以下のコードで事前に作成しておきます。
▼ダミーデータ作成コード (折りたたみ)ライブラリのインポート
import pickle
import numpyro
# CPU 環境: 論理デバイス数を増やしてparallel chainsを有効化。
# GPU 環境: CPU側の設定は無視され、物理GPUデバイスが使われる。
# (JAXのimportより前に実行する必要あり)
NUM_CHAINS = 4
numpyro.set_host_device_count(NUM_CHAINS)
import arviz as az
import jax
import jax.numpy as jnp
import jax.random as random
import matplotlib.pyplot as plt
import numpy as np
import numpyro.distributions as dist
import xarray as xr
from numpyro.distributions.transforms import CorrCholeskyTransform
from numpyro.infer import MCMC, NUTS, HMCGibbs, Predictive潜在効用$w$の初期値生成
MCMCを始める前に、観測された選択$y_i$と整合する$w$の初期値を用意する必要があります。選択ルールを満たさない初期値から始めると、Gibbsサンプリングの切断範囲が矛盾し、発散することがあるためです。
def initialize_w(y, P):
"""観測された選択yと整合する潜在効用wの初期値を生成する。
選択ルールを満たすように:
- 基準カテゴリPが選択された場合: 全成分を-1(全て負)
- 選択肢j+1が選択された場合: w[:,j] = 1.0, その他 = -0.5
Parameters
----------
y : (N,) 配列
各個体の観測選択 (1-indexed, Pが基準カテゴリ)
P : int
選択肢数
Returns
-------
w : (N, P-1) 配列
潜在効用の初期値
"""
N = y.shape[0]
Pm1 = P - 1
# デフォルト: 全成分 -1 (基準カテゴリ選択時の値)
w = -jnp.ones((N, Pm1))
for j in range(Pm1):
# y == j+1 -> 選択された成分なので 1.0
# y != P かつ y != j+1 -> 非選択・非基準なので -0.5
# y == P -> 基準カテゴリなので -1.0 (デフォルト値のまま)
w = w.at[:, j].set(jnp.where(y == j + 1, 1.0, jnp.where(y != P, -0.5, -1.0)))
return w上記では、観測された選択肢の成分を1.0、基準カテゴリ$P$が選択された場合は全成分を-1.0(≤ 0)、それ以外は-0.5としています。
Gibbsサンプリング関数
$\boldsymbol{w}$の各成分$w_{i,j}$を、他の成分を固定した切断正規分布から逐次サンプリングする関数を実装します。個体間は独立なのでjax.vmapで並列化できます。
def make_gibbs_fn(X, y, P):
"""潜在効用wのGibbsサンプリング関数を構築する。
wの各成分を、他の成分を条件とした切断正規分布から逐次サンプリングする。
個体間の並列計算はvmapで実装。
Parameters
----------
X : (N, P-1, D) 配列
前処理済み説明変数行列
y : (N,) 配列
観測選択 (1-indexed)
P : int
選択肢数
Returns
-------
gibbs_fn : callable
HMCGibbsに渡すGibbsサンプリング関数
"""
N, Pm1, D = X.shape
def gibbs_fn(rng_key, gibbs_sites, hmc_sites):
"""1回のGibbs更新: 全成分を逐次的にサンプリングする。
Parameters
----------
rng_key : PRNGKey
乱数キー
gibbs_sites : dict
Gibbsサンプリング対象のサイト {"w": (N, P-1) 配列}
hmc_sites : dict
HMCでサンプリングされたサイト {"beta", "sigma_rest", "R_chol"}
"""
# 現在のパラメータ値を取得
w = gibbs_sites["w"]
beta = hmc_sites["beta"]
sigma_rest = hmc_sites["sigma_rest"]
R_chol = hmc_sites["R_chol"]
# Sigmaを構築: Sigma = diag(sigma) @ R @ diag(sigma)
# L_Sigma = diag(sigma) @ R_chol (コレスキー因子)
sigma = jnp.concatenate([jnp.ones(1), sigma_rest])
L_Sigma = jnp.diag(sigma) @ R_chol
Sigma = L_Sigma @ L_Sigma.T
Sigma_inv = jnp.linalg.inv(Sigma)
# 各個体の平均ベクトル: mu_i = X_i @ beta, shape: (N, P-1)
mu = jnp.einsum("ijk,k->ij", X, beta)
# P-1個の選択肢ごとにループして、N個体の成分をサンプリング
w_curr = w
rng = rng_key
for j in range(Pm1):
# 1つの乱数キーから、次に使うキーとこのiterで使うキーを生成
rng, subkey = random.split(rng)
# N個体分の乱数キーを生成
keys = random.split(subkey, N)
def make_sample_fn(jj):
"""成分jjのサンプリング関数を生成する(jjを値キャプチャ)。"""
def sample_one(key_i, w_i, mu_i, y_i):
"""個体iについて成分jjを切断正規分布からサンプリングする。
Step 1: 精度行列を用いて条件付き正規分布のパラメータを計算
Step 2: 観測y_iに応じた切断範囲を決定
Step 3: 切断正規分布からサンプリング
"""
# --- Step 1: 条件付き正規分布のパラメータ ---
# 条件付き分散: σ²_{j|-j} = 1 / Σ^{-1}_{jj}
cond_var = 1.0 / Sigma_inv[jj, jj]
cond_std = jnp.sqrt(cond_var)
# 残差ベクトル: r_i = w_i - μ_i
r = w_i - mu_i
# Σ^{-1}のjj行と残差の内積
s = jnp.dot(Sigma_inv[jj], r)
# jj成分自身の寄与を除去
s_mj = s - Sigma_inv[jj, jj] * r[jj]
# 条件付き平均: μ_{j|-j} = μ_{ij} - σ²_{j|-j} * s_{-j}
cond_mean = mu_i[jj] - cond_var * s_mj
# --- Step 2: 切断範囲 [lo, hi] の決定 ---
# clipを使い、y_i==Pのときは、chosen=Pm1-1(=P-2)になるようにする
chosen = jnp.clip(y_i - 1, 0, Pm1 - 1)
is_base = y_i == P # 基準カテゴリが選択されたか
is_chosen = jj == chosen # 成分jjが選択された選択肢か
# jj以外の成分の最大値を計算 (jj成分を-infに置換)
w_masked = w_i.at[jj].set(-jnp.inf)
max_others = jnp.max(w_masked)
# Case 1: 基準カテゴリ選択 -> w_j ≤ 0
# Case 2: 成分jjが選択 -> w_j > max(0, max_others)
# Case 3: 他の成分が選択 -> w_j < w_{chosen}
lo = jnp.where(
is_base,
-jnp.inf,
jnp.where(is_chosen, jnp.maximum(0.0, max_others), -jnp.inf),
)
hi = jnp.where(
is_base,
0.0,
jnp.where(is_chosen, jnp.inf, w_i[chosen]),
)
# --- Step 3: 切断正規分布からのサンプリング ---
new_val = dist.TruncatedNormal(
loc=cond_mean, scale=cond_std, low=lo, high=hi
).sample(key_i)
# w_iの成分jjを更新して返す
return w_i.at[jj].set(new_val)
return sample_one
# 全個体をvmapで並列にサンプリング
w_curr = jax.vmap(make_sample_fn(j))(keys, w_curr, mu, y)
return {"w": w_curr}
return gibbs_fnここでのポイントは2つです。
- 条件付き正規分布のパラメータ計算:前述の$\mu_{j|-j}$と$\sigma^2_{j|-j}$の計算を、精度行列$\Sigma^{-1}$を使って効率的に行っています。精度行列の対角成分の逆数が条件付き分散になります。
- 切断範囲の設定:観測$y_i$の3パターン(基準カテゴリ$P$を選択・選択肢$j$を選択・他を選択)を
jnp.whereで分岐なしに記述しています。
(JAXはPythonのif分岐をJITコンパイルできないため、このように書く必要があるそう)
モデル定義
NumPyroでのモデル定義は、HMCでサンプリングするパラメータ($\beta$, $\sigma_{\text{rest}}$, $R_{\text{chol}}$)と、潜在変数$\boldsymbol{w}$の分布を宣言するだけです。
def mnp_model(X, y, P):
N, Pm1, D = X.shape
Pm2 = P - 2
# beta の事前分布 -> 正規分布
beta = numpyro.sample(
"beta", dist.MultivariateNormal(jnp.zeros(D), 5.0 * jnp.eye(D))
)
# sigma[1:]の事前分布 -> 半正規分布
# (sigma[0]=1は識別制約のため固定)
sigma_rest = numpyro.sample(
"sigma_rest", dist.HalfNormal(2.0 * jnp.ones(Pm2)).to_event(1)
)
# 相関行列のコレスキー因子の事前分布 -> LKJ (concentration=で一様分布)
R_chol = numpyro.sample("R_chol", dist.LKJCholesky(Pm1, concentration=1.0))
# Sigmaを構築
sigma = jnp.concatenate([jnp.ones(1), sigma_rest])
L_Sigma = jnp.diag(sigma) @ R_chol
Sigma = L_Sigma @ L_Sigma.T
numpyro.deterministic("Sigma", Sigma)
# 潜在効用wの分布: w | beta, Sigma ~ MVN(mu, Sigma)
# HMCではwは所与だが、log p(w | beta, Sigma)を計算するために定義が必要
mu = jnp.einsum("ijk,k->ij", X, beta) # (N, P-1)
numpyro.sample("w", dist.MultivariateNormal(mu, scale_tril=L_Sigma).to_event(1))numpyro.deterministic("Sigma", Sigma)で$\Sigma$をサイトとして記録しておくと、後でMCMCサンプルから簡単に取り出せて便利です。
MCMC実行
MCMCを実行する前に、初期値の設定に少し工夫が必要です。というのも、HMCGibbsにおけるNUTSは非制約空間で動作する関係上、init_paramsには各パラメータを非制約値へ変換した値を渡す必要があります。
# データ読み込み
with open("gen_data.pkl", "rb") as f:
gen_data = pickle.load(f)
X = jnp.array(gen_data["X"]) # (N, P-1, D)
y = jnp.array(gen_data["y"]) # (N,), 1-indexed
P = gen_data["Sigma"].shape[0] + 1
N, Pm1, D = X.shape
Pm2 = P - 2
# --- wの初期値を生成 ---
# 観測yと整合する値を設定し、MCMCの初期収束を担保する
w_init = initialize_w(y, P)
# --- Gibbsサンプリング関数を構築 ---
gibbs_fn = make_gibbs_fn(X, y, P)
# --- 全パラメータの初期値を設定 ---
# init_params: mcmc.run() に渡す非制約空間での初期値
# HMCGibbsではgibbs_sites("w")はinit_strategyで設定できないため、全サイトをここで明示的に指定する。
# HMCサイトは非制約空間への変換が必要:
# beta : 制約なし -> そのまま
# sigma_rest: HalfNormal (正値) -> log変換
# R_chol : LKJCholesky -> CorrCholeskyTransformの逆変換
Pm2 = P - 2
R_chol_init = jnp.eye(Pm1)
init_params = {
"w": w_init,
"beta": jnp.zeros(D),
"sigma_rest": jnp.zeros(Pm2), # log(1) = 0
"R_chol": CorrCholeskyTransform().inv(R_chol_init),
}HMCGibbsカーネルを構築し、MCMCを実行します。
kernel = HMCGibbs(
NUTS(
mnp_model,
target_accept_prob=0.85,
max_tree_depth=20,
init_strategy=init_to_value(values=init_values),
),
gibbs_fn=gibbs_fn,
gibbs_sites=["w"],
)
mcmc = MCMC(
kernel,
num_warmup=10000,
num_samples=2000,
num_chains=num_chains,
thinning=10,
progress_bar=True,
chain_method="parallel",
)
# 各チェーンに同じ初期値をブロードキャスト
init_params_chains = jax.tree.map(
lambda v: jnp.broadcast_to(v, (num_chains,) + v.shape), init_params
)
mcmc.run(random.PRNGKey(0), X, y, P, init_params=init_params_chains)結果の確認
ArviZを使ってMCMCの収束診断と可視化を行います。
idata = az.from_numpyro(mcmc)
# R-hat, ESS などの収束診断指標
summary_df = az.summary(idata)
summary_df.to_csv("summary.csv"),mean,sd,hdi_3%,hdi_97%,mcse_mean,mcse_sd,ess_bulk,ess_tail,r_hat
"R_chol[0, 0]",1.0,0.0,1.0,1.0,0.0,,4000.0,4000.0,
"R_chol[0, 1]",0.0,0.0,0.0,0.0,0.0,,4000.0,4000.0,
"R_chol[0, 2]",0.0,0.0,0.0,0.0,0.0,,4000.0,4000.0,
"R_chol[1, 0]",-0.103,0.29,-0.645,0.416,0.019,0.009,219.0,354.0,1.03
"R_chol[1, 1]",0.949,0.068,0.818,1.0,0.004,0.005,455.0,493.0,1.01
"R_chol[1, 2]",0.0,0.0,0.0,0.0,0.0,,4000.0,4000.0,
"R_chol[2, 0]",-0.263,0.226,-0.658,0.181,0.013,0.007,304.0,401.0,1.02
"R_chol[2, 1]",-0.269,0.283,-0.785,0.248,0.019,0.009,211.0,248.0,1.02
"R_chol[2, 2]",0.84,0.147,0.548,1.0,0.011,0.009,188.0,270.0,1.03
"Sigma[0, 0]",1.0,0.0,1.0,1.0,0.0,,4000.0,4000.0,
...# トレースプロット
az.plot_trace(
idata,
var_names=["beta", "sigma_rest", "R_chol"],
combined=True,
backend_kwargs={"constrained_layout": True},
)
plt.tight_layout()
plt.savefig("traceplot.png", dpi=150, bbox_inches="tight")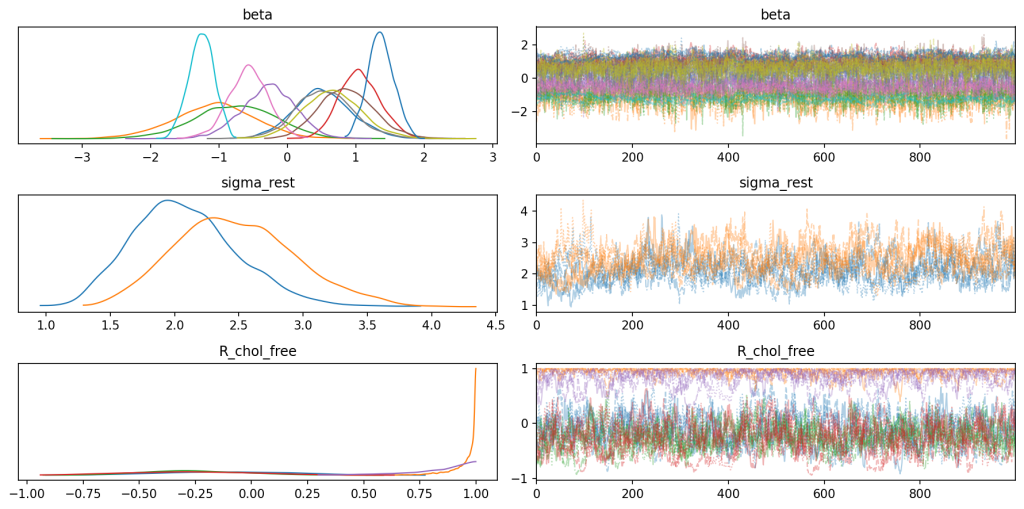
事後予測は以下で実行できます。
# --- 事後予測 ---
# samplesには"w"(Gibbsサイト)と"Sigma"(deterministic)が含まれるが、
# Predictiveに渡すと"w"が条件付けサイトとして固定され出力に現れなくなる。
# HMCパラメータのみを渡すことで"w"をモデルから予測させる。
hmc_samples = {k: samples[k] for k in ("beta", "sigma_rest", "R_chol")}
predictive = Predictive(mnp_model, posterior_samples=hmc_samples)
pred_out = predictive(random.PRNGKey(42), X, y=None, P=P)
# w_pred: (num_samples, N, P-1)
w_pred = np.array(pred_out["w"])
# 選択肢を決定: argmax+1 (1-indexed)、全成分≤0なら基準カテゴリP
max_w = w_pred.max(axis=-1) # (num_samples, N)
chosen = w_pred.argmax(axis=-1) + 1 # (num_samples, N)
y_pred = np.where(max_w < 0, P, chosen) # (num_samples, N)まとめ
今回は、HMC+Gibbsサンプリングを併用した多項プロビットモデルのMCMCについて紹介しました。
ここまで長々と書いておいて何なんですが、
- 説明変数の複雑な前処理が必要
- PPLを使う場合でも、事前分布や尤度の記述だけでなく、Gibbsサンプラーの設計も必要
と、多項プロビットやそのMCMCはけっこうめんどくさいポイントがあることがわかったので、多項ロジットですむのであればそちらを使ったほうがラクだなと思いました。
(多項プロビットのMCMCについて、全然情報が見つからなかったのも納得)
一方で、NumPyroのカスタマイズ性の高さ自体は素直にすごいなと思いました。ただドキュメントが(現状は)あまり整備されていなかったので、実装ハードルは低いとは言えないなと感じました。
参考