業務で時系列データの予測モデルを作る時、私は基本的にProphetを最初に選択します。なかなかの精度のモデルが、手早く簡単に作れるからです。
しかし、時系列データが数百系列あるような場合、いかにProphetといえどもモデルを数百個作成することになり、計算に時間がかかりますし、保守とか管理もめんどくさくなります。
(パラメータチューニングも考えるとなおさら)
VARや状態空間モデルのような、多変量時系列の予測に使える手法もありはするんですが、さすがに数百系列のデータの適応するのには無理があります。
そこで、今回はDeepARという深層学習を使った時系列予測アプローチを使い、モデル1つで複数系列データを予測する方法をご紹介します。
DeepARとは?
DeepARは、Amazonが開発した時系列予測フレームワークです。論文はこちら。
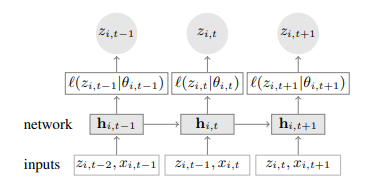
ざっくり説明すると、目的値$z_{i,t}$そのものを予測するのではなく、$z_{i,t}$がしたがう分布のパラメータ$\theta_{i,t}$を、特徴量$x_{i,t}$や前の値$z_{i,t-1}$を用いて構築する、というアプローチです。
$\theta_{i,t}$は、例えば$z_{i,t}$が正規分布にしたがうとすると、その平均や標準偏差をLSTMを使って計算します。
このようなアプローチをとることで、予測を「点」でなく「幅」で行うことができ、「将来値がどこからどこまでの範囲の値を取りそうか」を表現することができます。これが役に立つのは、例えば需要予測です。
スーパーなどの小売店では、商品が思ったより売れず在庫を抱えるより、想定以上に売れしまったことによる欠品を嫌います。得られるはずだった利益を逃してしまったことになる(機会損失)からです。
そこで、売上個数などをあらかじめ「幅」で予測し、その区間の上位値を仕入れに使います。例えば上位75%値が100だったとすると、「売上個数は75%の確率で100個以下になる」という予測がモデルによってなされたことを意味します。このような使い方をすると、欠品リスクを回避しやすくなります(もちろん在庫余剰のリスクは増える)。
またこの「幅」の広さは、「このモデルの予測がどれくらい自信があるか」を表しています。(幅が狭いと自信アリ、広いと自信ない)
まあこの「幅で予測」っていうのは、ProphetやARIMA、VARや状態空間モデルでも可能なんですが、「多変量データの時系列予測をやりたい」となると上述の通りこれらの手法では厳しいです。
一方DeepARは、幅での予測が可能なことに加え、1つのモデルで複数系列の予測が可能なので、強力な選択肢となり得ます。
Pythonで実装
ではDeepARを使った多変量データの予測モデルを構築してみます。今回はcovid-19感染者を都道府県別に予測します。
ただし、特徴量は使わず、過去のデータ$z_{i,t}$だけを用いたモデルにします。また精度の追求はせず、複数系列のためのDeepARモデルの実装方法の紹介が主題です。なので精度そこまで出てませんがご了承ください…。
まず、事前に必要なライブラリをインストールしておきます。DeepARモデルの構築にはgluontsというライブラリを使います。glutontsでは、DeepAR以外の深層学習を使った時系列モデルにも対応しているようです。(他のモデルについてもいつかブログで取り上げたい)
また、gluontsは深層学習フレームワークmxnexをベースとしているため、こちらも事前にインストール。
pip install gluonts mxnetPythonで必要なライブラリをインポートします。上の2つは一般的なライブラリです。
import pandas as pd
import numpy as np
import random
from gluonts.dataset import common
from gluonts.model import deepar
from gluonts.mx.trainer import Trainer
from gluonts.evaluation.backtest import make_evaluation_predictions
import mxnet
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdmcovid-19感染者のデータを読み込みます。厚生労働省のHPでオープンデータとして公開されているので利用させていただきます。
df = pd.read_csv('https://covid19.mhlw.go.jp/public/opendata/newly_confirmed_cases_daily.csv')
df['Date'] = pd.to_datetime(df['Date']) # 日付型に変換
df = df.drop(columns='ALL') # 合計の列は削除
df = df.set_index('Date').stack().reset_index() # 縦持ちに変換
df.columns = ['Date', 'Pref', 'Value'] # 列名を指定こんな形式のデータになります。Prefが都道府県名、Valueが感染者数です。
47系列もあると何が何だか分からないですが、とりあえず可視化してみます。
2022年頭の第6波は、感染者数で見ると今までとは桁違いだったことが分かりますね。(このブログ書いているときも第6波ど真ん中です)
fig, ax = plt.subplots(figsize=(15, 10))
sns.lineplot(x='Date', y='Value', data=df, hue='Pref', legend=True, ax=ax)
ax.legend(loc='upper left', bbox_to_anchor=(1, 1))
fig.show()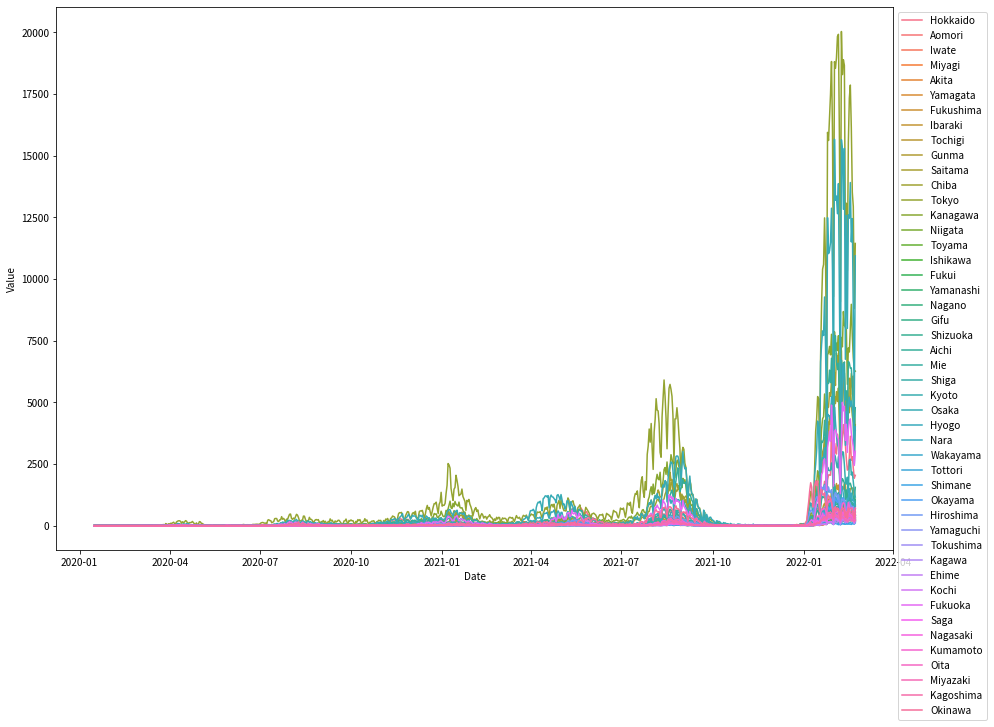
pandasのデータフレームではなく辞書形式にします。各Keyが都道府県名です。
list_pref = list(df['Pref'].unique()) # 都道府県
dict_df = dict()
for p in list_pref:
df_p = df[df['Pref']==p][['Date', 'Value']]
df_p = df_p.set_index('Date') # 日付列をインデックスへ
df_p.index.name = None
dict_df[p] = df_p # 辞書に格納していく
del df_pこれを使い、glutontsのListDatasetへ突っ込みます。直近14日のデータで精度検証したいので、学習用データにはラスト14日のデータは入れません。
テストデータも作成しますが、ラスト14日のデータだけでなく、全期間のデータを突っ込みます。(14日後を予測するためには、その前数日間のデータが必要なので)
train_data = common.ListDataset(
[
{
"start": dict_df[p].index[0],
"target": dict_df[p]['Value'][:-14] # 最後の14日は除外
} for p in list_pref
],
freq="d" # 単位は日
)
test_data = common.ListDataset(
[
{
"start": dict_df[p].index[0],
"target": dict_df[p]['Value']
} for p in list_pref
],
freq="d")ではモデル構築します。ハイパーパラメータは今回は決め打ちで。
データサイズもそんなにないので、数分で終わりました。
# シード固定
np.random.seed(123)
random.seed(123)
mxnet.random.seed(123)
estimator = deepar.DeepAREstimator(
freq='d',
prediction_length=14, # 将来14日を予測
context_length=14, # 予測に使うのは過去14日のデータ
num_cells=50, # セルの数
num_layers=2, # 層の数
trainer=Trainer(epochs=100, num_batches_per_epoch=47))
# 実行
predictor = estimator.train(training_data=train_data)精度検証をします。make_evaluation_predicitions関数を使えば、精度検証がしやすい形に値を返してくれます。
forecast_it, ts_it = make_evaluation_predictions(dataset=test_data, predictor=predictor, num_samples=100)
forecast = list(forecast_it) # 将来予測値の情報が入ったリスト
tss = list(ts_it) # テストデータに関するリスト
# tssをデータフレーム化
ts_entry = pd.concat([tss[i] for i in range(len(list_pref))], axis=1)
ts_entry.columns = list_pref
ts_entry
# forecastを辞書に格納
forecast_entry = dict(zip(list_pref, forecast))ts_entryはこんな感じ。
テスト期間における、実測値と予測値を可視化したグラフを描くために関数を定義します。
def plot_forecast(pref, interval, ax):
date_range = pd.date_range(
start=forecast_entry[pref].start_date,
periods=predictor.prediction_length,
freq='D')
# 予測期間+予測に用いたデータ期間の実測値を描画
ts_entry[pref][-(estimator.prediction_length + estimator.context_length):].plot(ax=ax)
# 予測値の中央値を描画
ax.plot(date_range, forecast_entry[pref].median, color='green')
# 予測区間も描画
q_upr = forecast_entry[pref].quantile(0.5 + interval / 2) # 区間の上側
q_lwr = forecast_entry[pref].quantile(0.5 - interval / 2) # 区間の下側
# 塗りつぶし
ax.fill_between(date_range,
q_lwr, q_upr,
facecolor='g',
alpha=0.3,
interpolate=True)
ax.set_title(pref)
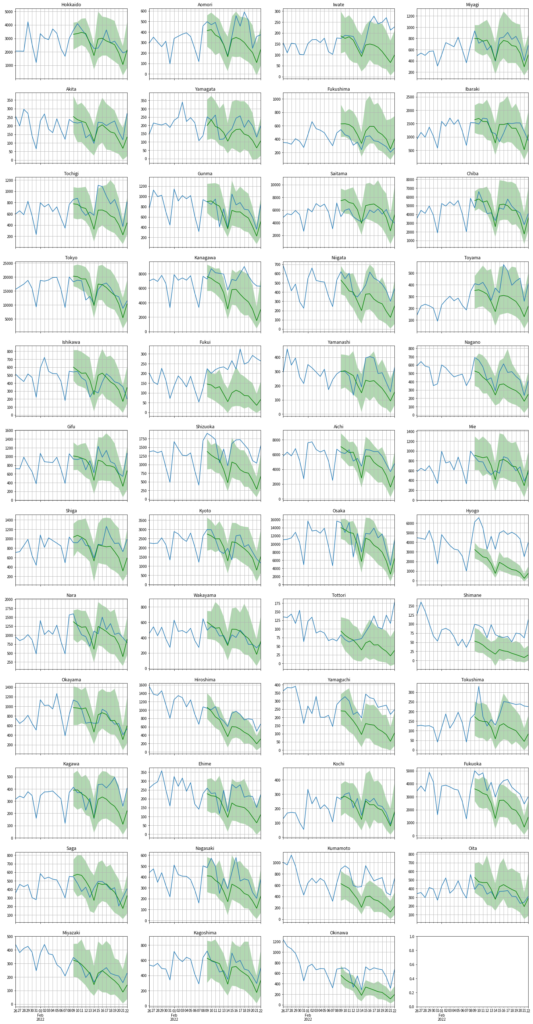
ax.grid(which='both')試しに東京の実測値&予測値を可視化してみます。予測区間は75%にしました。
精度がいいとは言い難いですが、傾向や曜日の周期性は割と追えているみたいです。
fig, ax = plt.subplots()
plot_forecast('Tokyo', interval=0.75, ax=ax)
fig.show()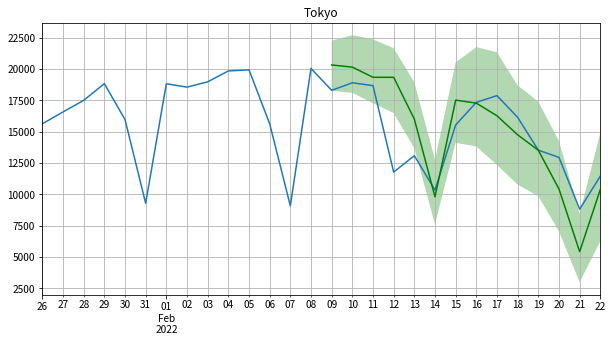
47都道府県すべて可視化してみました。どの都道府県でも「ダウントレンドになる」という予測になっているようです。
そのため、予想に反して感染者が増えたところ(岩手や福井)が大きく外してしまっています。
まあ今回は精度は度外視してるのでこんなもんかな。