時系列データのモデリングとして、以下のような手法がメジャーかなと思います。
- ARIMA
- Prophet
- 状態空間モデル
- RNN
- LSTM
- DeepAR
今回は、2021年に発表された比較的新しい手法であるGreykiteのご紹介をしていきます。
注意:本記事は2022年11月時点の情報をもとに記載しております。ライブラリの変更等により本記事の記載内容が古くなる可能性がありますが、ご了承ください。
Greykiteとは?
LinkedInが2021年にOSSとして公開した時系列予測モデルです。機械学習分野の国際会議であるKDD2022でも発表されたようです。
こちらの論文によると、LinkedInが提供しているサービスのリソース配分・パフォーマンス評価・ABテスト等の目的で使用されているようです。
解釈可能性と計算速度が売りらしく、論文中でもMeta(Facebook)が開発したProphetや、Amazonが開発したDeepARと比較されています。
- Prophet : 解釈可能だが計算スピードが遅い
- DeepAR : 予測手法としては強力だが解釈不可
また、Greykiteは厳密にいうと単一の手法というわけではなく、以下の3つの手法を統合し、どれでも好きなものを扱えるようにしたライブラリという位置づけです。
- Silverkite (Greykiteのメインとなる手法)
- Prophet
- Auto Arima
本記事でも、以降はGreykiteのメイン部分であるSilverkiteに焦点を当てていきます。
Silverkiteのアルゴリズム
Silverkiteでは、2つのフェーズに分けて時系列データをモデリングします。
- 条件つき平均のモデリング
- 不確実性のモデリング
つまり、フェーズ1にて各時点の値の平均を予測するモデルを作成し、その後、フェーズ1の予測値と実測値との乖離をもとに、各時点の不確実性(=予測区間)を算出するモデルを作成する、という流れになっています。
ProphetやDeepARでは、『各時点のデータは正規分布等の確率分布にしたがう』として確率モデルを構築→平均や分散のパラメータをデータから推測する、というロジックになっています。これは、確率分布を仮定することで”点”ではなく”幅”での予測を可能にし、意思決定などのための有用性を持たせるためです。
この”幅での予測”については、以前のDeepARについての投稿でもう少し詳しく記述してますので、よろしければそちらもご覧ください。
Silverkiteでは、”点”での予測と”幅での予測”を2つのモデルに分割して実行することで、計算負荷を下げスピードアップを可能にしている、と主張しているみたいです。
以下では、各フェーズの概要を説明していきます。
フェーズ1:条件つき平均のモデリング
時点$t$において使用可能な特徴量を$\mathcal{F}(t)$とすると、目的変数$Y(t)$の条件つき平均を以下のようにモデリングしています。
$$
E[Y(t)|\mathcal{F}(t)] = G(t) + S(t) + H(t) + A(t) + R(t) + I(t)
$$
まず最初の項$G(t)$は、トレンドを以下の式で表現しています。
$$
G(t) = \alpha_0 f(t) + \sum_{i=1}^k \alpha_i 1_{\{t>t_i\}} \left(f(t) – f(t_i)\right)
$$
$f(t)$は$t$の関数で、Silverkiteでは$f(t)=t$や$f(t)=\sqrt{t}$などの、$t$に関する増加関数が使用されます。後半の項はトレンドの変化を表現するために使われています。これらの項を重みづけする係数$\alpha_0$や$\alpha_i$を、パラメータとしてデータから推測します。
ちなみに変化点検出ですが、ざっくり以下の手順で行われているようです。
- データをサマり、粒度を荒くする(例:日次→週次)
- 変化時点の候補を等間隔に設定
- adaptive lassoを適用し、2の候補の中で変化量がある程度大きい点を変化点とする
(lassoだと変化点を縮約しすぎてしまうらしい)
続いて$S(t)$はデータの周期性を表現する項で、フーリエ級数によって定義されています。
$$
S_p(t) = \sum_{m=1}^M \left(a_m \sin(2\pi md(t)) + b_m \cos(2\pi md(t))\right)
$$
$d(t)$は各周期における時点$t$の相対的な位置を表現する関数で、0以上1以下の値をとります。例えば1日の周期性を表現する場合、以下のようになります。
$$
d(t) = \frac{\text{時点}t\text{での時間(hour)}}{24}
$$
データに複数の周期(年周期・週周期・日周期・etc)が存在する場合、各周期ごとに$S_p(t)$を設定し足し合わせることで$S(t)$を表現します。またトレンドと同様に、周期性も一定ではなく変化することを許容しています(詳細は省略)。推測するパラメータは、係数$a_m$や$b_m$となります。
$H(t)$はイベント・祝日の効果を表現する項で、時点$t$が事前に設定したイベント・祝日に当たる場合は1、そうでないときは0をとるダミー変数を作成し、その効果を推定します。また、各イベント・祝日の前後数日間にもダミー変数を設定することが可能です。
Silverkiteでは、各国の祝日情報が事前にライブラリに搭載されているので、ユーザーは『どの祝日を使用するか』『併せて前後何日間まで使用するか』の情報をインプットするだけで良いです。
$A(t)$には$Y(t)$のラグ効果が入ります。例えば、$Y(t-1)$や$Y(t-2)$、また移動平均$\frac{Y(t-1)+Y(t-2)+Y(t-3)}{3}$などを含めることができます。
ただし、この項が存在すると結果の解釈性が下がってしまうため、解釈性が目的ならこの$A(t)$は使わないほうがいいんじゃないのかな、というのが個人的な感想です。(予測だけが目的ならとりあえず設定しといて問題なし)
$R(t)$は、上記以外の特徴量$X(t)=\{X_1(t), \dots, X_p(t)\}$の影響を表現するための項です。ただし、$Y(t)$と同時点の$X(t)$を使用する場合、将来予測を行うためには$X(t)$の将来値$\hat{X}(t)$を何かしらの方法で準備する必要があります。もしくは、時点をいくつか遡った$X(t-h)$を使用することもできます。
$I(t)$は、これまで挙げてきた要素の交互作用を表現する項です。これを設定するとモデルの表現力は向上する一方、項の数が爆発的に増え結果の解釈が難しくなってしまうので、何も考えずに設定するのは個人的にはオススメしません。
Silverkiteではこれらの項を特徴量として設定した後、何かしらの手法で各係数パラメータを推定します。デフォルトではridge回帰が使われますが、オプションでlasso回帰やElastic netを使うこともできます。
フェーズ2:不確実性のモデリング
フェーズ1にて求めた条件つき平均$\hat{Y}(t)$を使い、実際の値との乖離$r(t)=Y(t)-\hat{Y}(t)$を計算します。その後、得られた複数の$r(t)$をもとに、モデルの予測区間を計算します。
また、単純に全ての$r(t)$を使用するのではなく、何かしらのカテゴリ変数を基準に$r(t)$をサブグループに分割し、各サブグループごとに予測区間を算出しています。
例えば、曜日を基準に$r(t)$を分割して予測区間を計算すると、曜日ごとに区間の幅が異なるモデルを作ることができます。
(例:「土日は予測が難しいので区間が広くなる」、「月曜日はいつも似た値をとるので、区間が狭くなる」)
区間の算出に使われる手法は2つあるようで、1つは$r(t)$の分布に正規分布$N(0,\sigma^2)$を仮定し、$\sigma$の値を推定するパラメトリックな方法です。もう1つは、経験累積分布関数(ECDF)を作成し、各分位点(2.5%点や97.5%点)を求めるノンパラメトリックな方法です。
ちなみにECDFの詳細については、こちらの記事が大変参考になりました。
Pythonでの実行
GreykiteはPython用ライブラリが公開されているので、誰でも簡単に使用できます。紹介したSilverkiteやProphet、Auto Arimaの実行はもちろんのこと、時系列データの探索的分析に役立つ可視化機能も充実しています。
導入もpip installするだけです。
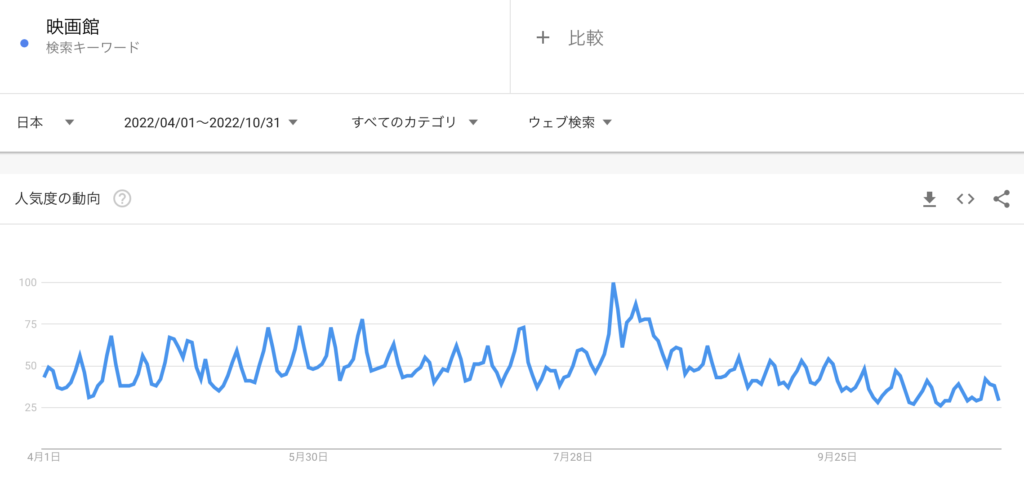
pip install greykite今回はGoogleトレンドから取得した”映画館”というワードの検索数(2022/4/1~10/31、日次データ)に対し、Greykiteのメイン手法であるSilverkiteを使って時系列モデルを構築します。
ではPythonを起動し、必要なライブラリを読み込みます。
import numpy as np
import pandas as pd
import plotly
from greykite.algo.changepoint.adalasso.changepoint_detector import ChangepointDetector
from greykite.algo.forecast.silverkite.constants.silverkite_column import SilverkiteColumn
from greykite.common.features.timeseries_features import get_available_holidays_across_countries
from greykite.framework.input.univariate_time_series import UnivariateTimeSeries
from greykite.framework.templates.autogen.forecast_config import ForecastConfig
from greykite.framework.templates.autogen.forecast_config import MetadataParam
from greykite.framework.templates.autogen.forecast_config import ModelComponentsParam
from greykite.framework.templates.forecaster import Forecaster
from greykite.framework.templates.model_templates import ModelTemplateEnum
from greykite.framework.utils.result_summary import summarize_grid_search_results保存したGoogleトレンドデータのcsvをpandasデータフレームで読み込みます。(csvは事前に列名やフォーマットを少しいじってます)
df = pd.read_csv('GoogleTrends_cinema.csv')
df['date'] = pd.to_datetime(df['date'])
df['value'] = df['value'].astype(int)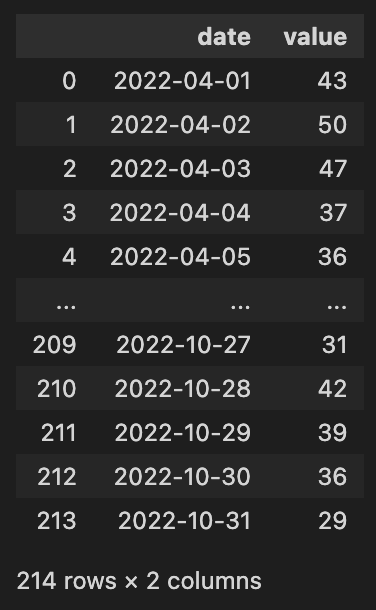
このデータフレームを、UnivariateTimeSeriesという形式に変換します。
ts = UnivariateTimeSeries()
ts.load_data(
df=df,
time_col="date", # 日付の列
value_col="value", # 値の列
freq="D" # 日付の単位
)一旦可視化してみます。以下のように簡単にplotlyによるトレースプロットが作れます。
fig = ts.plot()
plotly.io.show(fig)概形を見やすくするために、7日ごとに平均をとって可視化してみます。
fig = ts.plot_grouping_evaluation(
# デフォルトでは平均を計算する(任意の集計方法を指定可能)
groupby_sliding_window_size=7, # 集計する粒度(7の場合、t-3~t+3の7日間の平均を計算)
title="Weekly average")
plotly.io.show(fig)このグラフを見ると、5月のGW付近・8月のお盆辺りに大きな増減が見てとれるので、トレンドの変化があったことが窺えます。
注意:GWやお盆の変化は、本来「トレンド」ではなく「年周期」か「イベント・祝日」に含まれると考えるほうが自然です。今回はデータが半年分しかなく、「年周期」「イベント・祝日」のいずれも識別不可なので、今回は「トレンド」として取り扱うことにします。
次に週周期(=曜日による違い)を可視化してみます。月曜日=1、日曜日=7なので、”映画館”と検索する人が一番多いのは土曜日であることが分かります。
fig = ts.plot_quantiles_and_overlays(
groupby_time_feature="dow", # "day of week"の略
show_mean=True, # 平均も描画
show_quantiles=[0.1, 0.5, 0.9], # 各分位点も描画
center_values=True # 中央化の有無
)
plotly.io.show(fig)それでは、Silverkiteを実行してみます。まずメタデータというものを設定します、
metadata = MetadataParam(
time_col="date", # 日付の列名
value_col="value", # 値の列名
freq="D" # 日付の単位
)その後、14日後までを予測するモデルを構築します。一旦ハイパーパラメータ等の設定は弄らないでやってみます。
forecaster = Forecaster()
result = forecaster.run_forecast_config(
df=df,
config=ForecastConfig(
model_template=ModelTemplateEnum.SILVERKITE.name,
forecast_horizon=14,
coverage=0.95, # 予測区間を95%に設定
metadata_param=metadata
)
)モデルの回帰係数を出力してみます。
print(result.model[-1].summary(max_colwidth=50))以下は出力結果の抜粋ですが、Chinese New YearやIndependence Dayなど、外国の祝日が特徴量として含まれています。どうやら、デフォルト設定の際に特徴量として設定される祝日があらかじめ決められているようです。
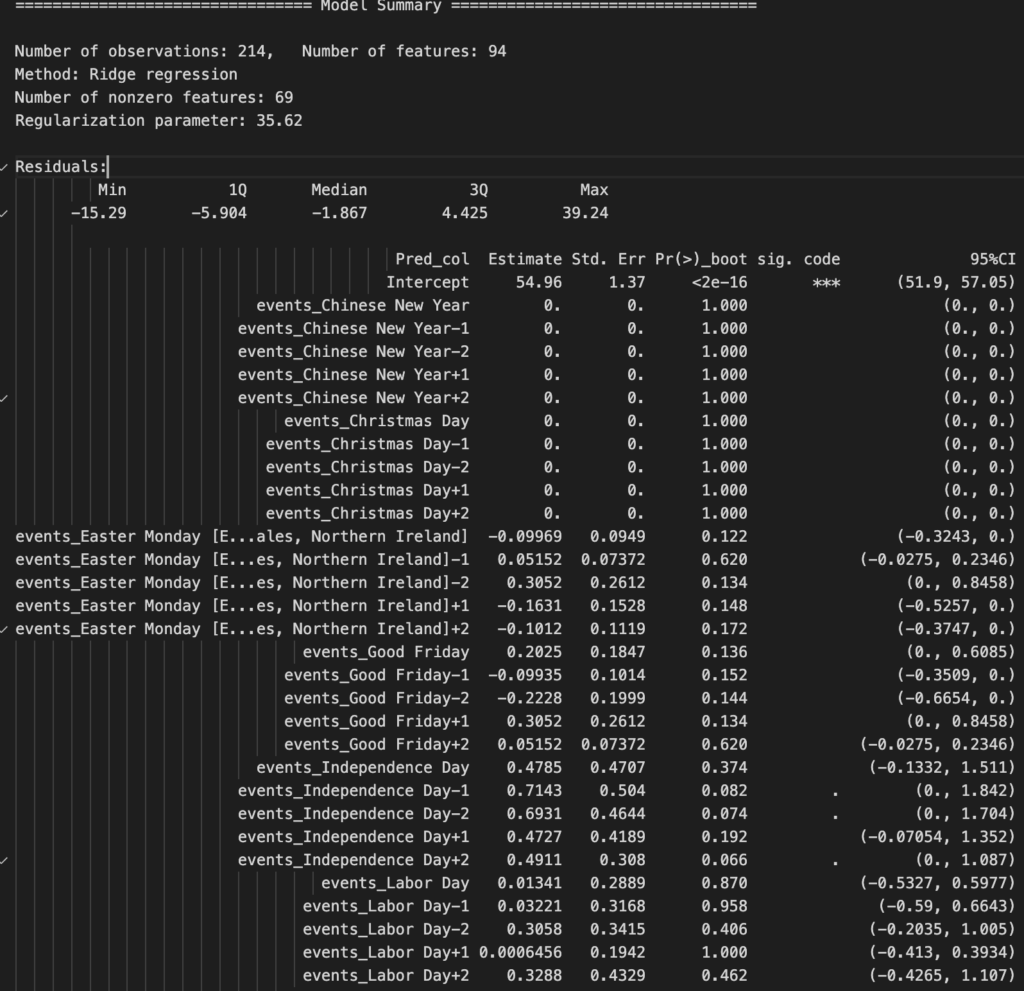
また、目的変数のラグや交互作用項もたくさん入ってきているので、この結果だけを見るとお世辞にも『解釈性の高いモデル』とは言えないと思います。
▼回帰係数 全出力結果(折りたたみ)モデルの予実をプロットしてみると、精度も良くなさそうです。
backtest = result.backtest
fig = backtest.plot()
plotly.io.show(fig)モデルを各要素に分解して可視化します。autoregressionとeventsの波形がよく分からないことになっていますね。
fig = result.forecast.plot_components()
plotly.io.show(fig)このように、Silverkiteを何も考えずデフォルトで実行するのは精度面でも解釈性の面でも避けたほうが良さげです。
では、デフォルトではなく今回のデータにフィットした設定で再実行してみます。
その前に、トレンドの変化点に関する設定を少し探ってみます。前述のようにデータをサマり、粒度を荒くした値に対して変化点検出を実行します。今回は年周期を仮定していないので、以下の関数内の
regularization_strengthpotential_changepoint_n
を何パターンか試してみて、良さげな値を見つけます。
model = ChangepointDetector()
res = model.find_trend_changepoints(
df=df, # データフレーム
time_col="date", # 日付の列名
value_col="value", # 値の列名
yearly_seasonality_order=0, # 年周期を表現するためのフーリエ級数の次数(今回は年周期を仮定してないので0)
regularization_strength=0.5, # adaptive lassoの罰則の強さ(0~1の値)
resample_freq="7D", # データを括る粒度
potential_changepoint_n=20, # 変化点の数、値を大きくすると計算負荷が高くなる
yearly_seasonality_change_freq=None, # 年周期の値が変わる間隔(今回は年周期ないので無視)
no_changepoint_distance_from_end="14D", # ラスト14日は変化点なし
actual_changepoint_min_distance="7D" # 変化点どうしの感覚は最低7日空ける
)
fig = model.plot(
observation=True,
trend_estimate=False,
trend_change=True,
yearly_seasonality_estimate=False,
adaptive_lasso_estimate=True,
plot=False)
plotly.io.show(fig)何となく良さそうですので、トレンドまわりの設定はこれを用いることにします。
では、各ハイパーパラメータを以下のように設定し再実行します。いろいろ設定してますが、1つだけピックアップすると、uncertaintyでconditional_colsに"month"を設定することで予測区間が月ごとに変わるようにしています。これは、区間を全期間で同じにしてしまうと、GWやお盆など予測が難しい期間に引っ張られ、全期間での予測区間が広くなってしまうことを防ぐために設定してみました。
growth = {
"growth_term": "linear" # 線形トレンド
}
changepoints = {
"changepoints_dict": {
"method": "auto",
"yearly_seasonality_order": 0,
"regularization_strength": 0.5,
"resample_freq": "7D",
"potential_changepoint_n": 20,
"yearly_seasonality_change_freq": None,
"no_changepoint_distance_from_end": "14D",
"actual_changepoint_min_distance": "7D"
}
}
seasonality = {
"yearly_seasonality": False,
"quarterly_seasonality": False,
"monthly_seasonality": False,
"weekly_seasonality": 2, # 週周期の次数
"daily_seasonality": False
}
events = {
"holiday_lookup_countries": None # 祝日なし
}
model_components = ModelComponentsParam(
seasonality=seasonality,
growth=growth,
changepoints=changepoints,
autoregression={
"autoreg_dict": None # 自己回帰の項なし
},
events=events,
regressors=None, # 説明変数なし
lagged_regressors={
"lagged_regressor_dict": None # 説明変数のラグも当然なし
},
custom={
"fit_algorithm_dict": {
"fit_algorithm": "ridge"
},
"feature_sets_enabled": {
SilverkiteColumn.COLS_DAY_OF_WEEK: False, # 曜日ダミーの有無
SilverkiteColumn.COLS_TREND_WEEKEND: False, # 平日/週末とトレンドとの交互作用の有無
SilverkiteColumn.COLS_TREND_DAY_OF_WEEK: False, # 曜日とトレンドとの交互作用の有無
SilverkiteColumn.COLS_TREND_WEEKLY_SEAS: False # 週周期の変化を許容するかどうか
}
},
uncertainty={
"uncertainty_dict": {
"uncertainty_method": "simple_conditional_residuals",
"params": {
"quantiles": [0.025, 0.975],
"conditional_cols": ["month"], # 予測区間を月ごとに計算する
"quantile_estimation_method": "normal_fit"
}
},
}
)
# 実行
custom_result = forecaster.run_forecast_config(
df=df,
config=ForecastConfig(
model_template=ModelTemplateEnum.SILVERKITE.name,
forecast_horizon=14,
coverage=0.95, # 95% prediction intervals
model_components_param=model_components,
metadata_param=metadata
)
)結果を可視化してみると、先ほどのデフォルト設定モデルよりtrain期間・test期間どちらにおいても精度が上がってそうです。
backtest = custom_result.backtest
fig = backtest.plot()
plotly.io.show(fig)回帰係数も見てみます。デフォルトモデルよりもスッキリしており、解釈性も向上していると言えます。
print(custom_result.model[-1].summary(max_colwidth=50))================================ Model Summary =================================
Number of observations: 214, Number of features: 17
Method: Ridge regression
Number of nonzero features: 17
Regularization parameter: 1.487
Residuals:
Min 1Q Median 3Q Max
-18.75 -4.611 -1.413 2.564 33.17
Pred_col Estimate Std. Err Pr(>)_boot sig. code 95%CI
Intercept 58.09 1.64 <2e-16 *** (55.11, 61.36)
ct1 7.961 1.191 <2e-16 *** (5.56, 10.08)
sin1_tow_weekly -13.9 1.525 <2e-16 *** (-16.65, -10.74)
cos1_tow_weekly -5.406 1.258 <2e-16 *** (-7.945, -3.093)
sin2_tow_weekly 1.017 1.408 0.454 (-1.803, 3.657)
cos2_tow_weekly -5.427 1.388 <2e-16 *** (-8.353, -2.842)
cp0_2022_04_15_00 6.633 1.074 <2e-16 *** (4.421, 8.499)
cp1_2022_04_29_00 3.22 1.3 0.012 * (0.752, 5.763)
cp2_2022_05_27_00 -1.282 1.352 0.358 (-3.774, 1.355)
cp3_2022_06_10_00 -1.468 1.558 0.350 (-4.509, 1.393)
cp4_2022_07_01_00 2.479 1.343 0.062 . (-0.249, 4.964)
cp5_2022_07_08_00 2.385 1.242 0.042 * (-0.001409, 4.619)
cp6_2022_07_22_00 -0.2422 1.568 0.850 (-3.371, 2.68)
cp7_2022_07_29_00 -5.169 1.673 0.004 ** (-8.754, -1.652)
cp8_2022_08_12_00 -16.92 2.825 <2e-16 *** (-22.09, -10.83)
cp9_2022_08_19_00 -13.23 1.64 <2e-16 *** (-16.1, -9.87)
cp10_2022_09_02_00 -2.421 1.866 0.196 (-6.029, 1.452)
Signif. Code: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Multiple R-squared: 0.6108, Adjusted R-squared: 0.5984
F-statistic: 42.56 on 6 and 206 DF, p-value: 1.110e-16
Model AIC: 2039.0, model BIC: 2064.7
WARNING: the F-ratio and its p-value on regularized methods might be misleading, they are provided only for reference purposes.
各要素を可視化してみます。これまた先ほどよりだいぶ見やすいですね。
fig = custom_result.forecast.plot_components()
plotly.io.show(fig)テストデータにおける各精度指標を見てみます。MAPE=14.4なので精度良いとは言い難いですが、今回は一旦これで良しとします。
custom_result.backtest.test_evaluation{'CORR': 0.7795377243319328,
'R2': -0.5013176497656533,
'MSE': 32.97536980735274,
'RMSE': 5.742418463274228,
'MAE': 4.608060702798177,
'MedAE': 3.618613140386289,
'MAPE': 14.356654858689591,
'MedAPE': 12.490086935017686,
'sMAPE': 8.070290748847933,
'Q80': 3.5740976104090336,
'Q95': 4.209131239914006,
'Q99': 4.378473541115333,
'OutsideTolerance1p': 1.0,
'OutsideTolerance2p': 0.9285714285714286,
'OutsideTolerance3p': 0.8571428571428571,
'OutsideTolerance4p': 0.7857142857142857,
'OutsideTolerance5p': 0.7857142857142857,
'Outside Tolerance (fraction)': None,
'R2_null_model_score': None,
'Prediction Band Width (%)': 42.19481212688354,
'Prediction Band Coverage (fraction)': 0.7142857142857143,
'Coverage: Lower Band': 0.07142857142857142,
'Coverage: Upper Band': 0.6428571428571429,
'Coverage Diff: Actual_Coverage - Intended_Coverage': -0.23571428571428565}まとめ
今回はLinkedInの開発した時系列モデル”Greykite”、およびそのメイン手法である”Silverkite”を解説しました。ProphetやAuto ARIMAも使える点、設定によっては解釈性と予測性能のいずれかに全振りできる点を考えると、Greykiteはかなり自由度は高い手法であると言えそうです。
一方で設定する項目がかなり多いため、パラメータチューニングには結構な労力がかかるなと思いました。またそれを考慮すると、「ホントにProphetより計算はやいのかしら」という疑問も持ちました。余力があれば計算時間の比較など今度試してみようと思います。
参考: